


Abridge is one of the fastest-growing AI companies in healthcare. This year, the enterprise-grade AI platform for clinical conversations is projected to support more than 80 million patient-clinician conversations across 250 of the largest and most complex health systems in the U.S. With that expansion comes a familiar engineering challenge: the infrastructure that supported a small initial team of developers doesn’t scale to meet skyrocketing demand.
More health systems means more feature requirements. More features means more engineers. More engineers means more machines, more configurations, more drift, and more time that ML Infra teams have to spend keeping the lights on instead of building. At a certain scale, developer tooling stops being a convenience and starts being a constraint on how fast the business can move.
This is the story of how Abridge rearchitected its developer infrastructure using Coder and transformed developer onboarding time from days to minutes.

The scaling problem is a compounding problem
To build for the complex realities of healthcare, Abridge relies on several developer archetypes working in parallel: clinical scientists processing sensitive data, ML researchers training and evaluating models on GPU clusters, product engineers building APIs and inference services, and PMs prototyping internal dashboards and prototypes. Each archetype has different resource requirements, different compliance constraints, and a different tolerance for infrastructure complexity.
As the team grows, the friction compounds. An ML Infra engineer debugging a colleague's environment is an ML Infra engineer not building infrastructure. A clinical scientist blocked on cloud access is a clinical scientist not building data intake workflows. The compounding effect is the real problem: every hour of environment overhead is an hour not spent on the 100+ data intake workflows and 50 ML models that are core to the product.
Infrastructure as code, all the way down
The foundation of the current setup is a Terraform-based workspace system deployed on GCP. Everything that defines how a workspace behaves lives in version control: compute sizing, network policy, secrets management, compliance controls, lifecycle rules, and cost tracking. No one needs admin access to a UI to change how workspaces behave. Changes go through PRs and CI like everything else.
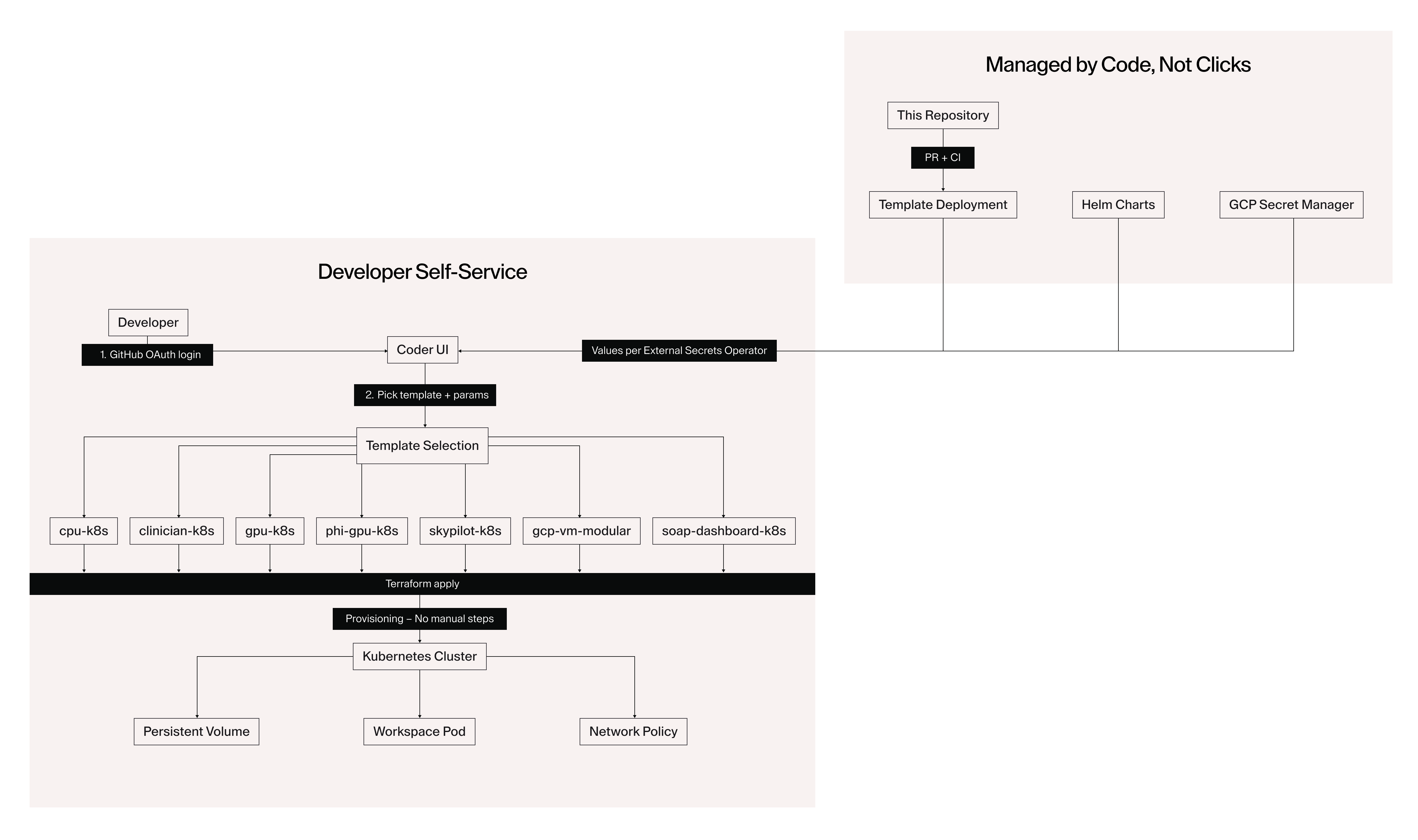 The full system architecture: developer self-service on the left, GitOps-driven control plane on the right. Every workspace type that flows through Terraform applies to the Kubernetes cluster with no manual steps.
The full system architecture: developer self-service on the left, GitOps-driven control plane on the right. Every workspace type that flows through Terraform applies to the Kubernetes cluster with no manual steps.
We organized the architecture into three layers. Shared modules form the base, providing standardized resource definitions and reusable utilities that every template inherits. Templates sit in the middle, encoding workspace behavior for each developer archetype. The control plane sits at the top, managing the Coder server itself via Helm with per-environment value overrides for dev, staging, and production.
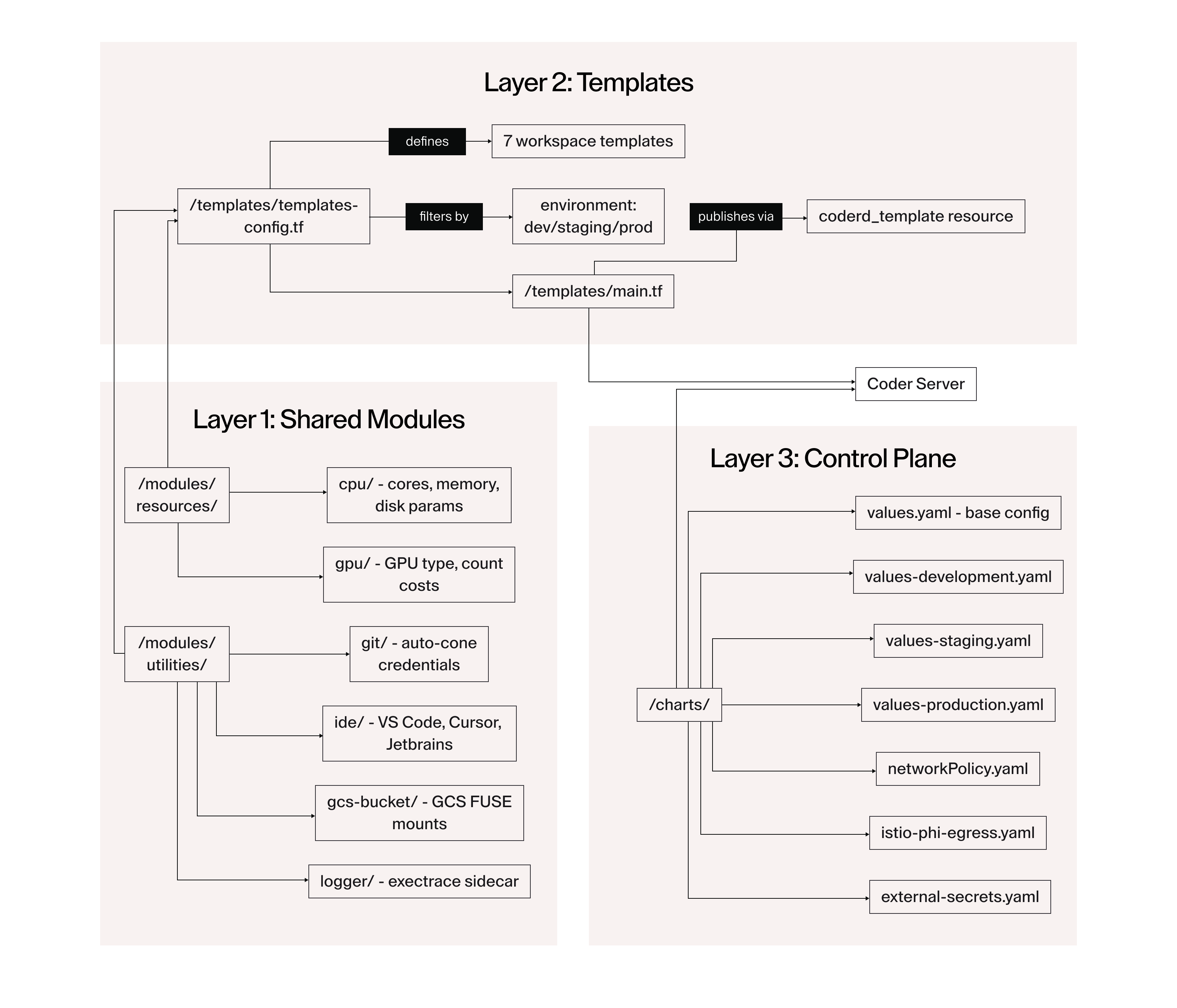 The three-layer architecture: shared modules define resource parameters and utilities; templates consume them to define workspace types; the control plane manages secrets, auth, networking, and per-environment config via Helm and Istio.
The three-layer architecture: shared modules define resource parameters and utilities; templates consume them to define workspace types; the control plane manages secrets, auth, networking, and per-environment config via Helm and Istio.
Abridge maintains seven Terraform-based templates covering the full range of developer needs:
| Template | Use Case |
|---|---|
cpu-k8s | Standard dev workspaces |
clinician-k8s | CPU workspaces with Phoenix observability sidecar |
gpu-k8s | ML/AI workspaces with L4/H100 GPU access |
phi-gpu-k8s | PHI-compliant, air-gapped GPU workspaces |
gcp-vm-modular | GCP VMs with deep learning images |
skypilot-k8s | Multi-cloud job orchestration |
soap-dashboard-k8s | Dashboard dev for PMs |
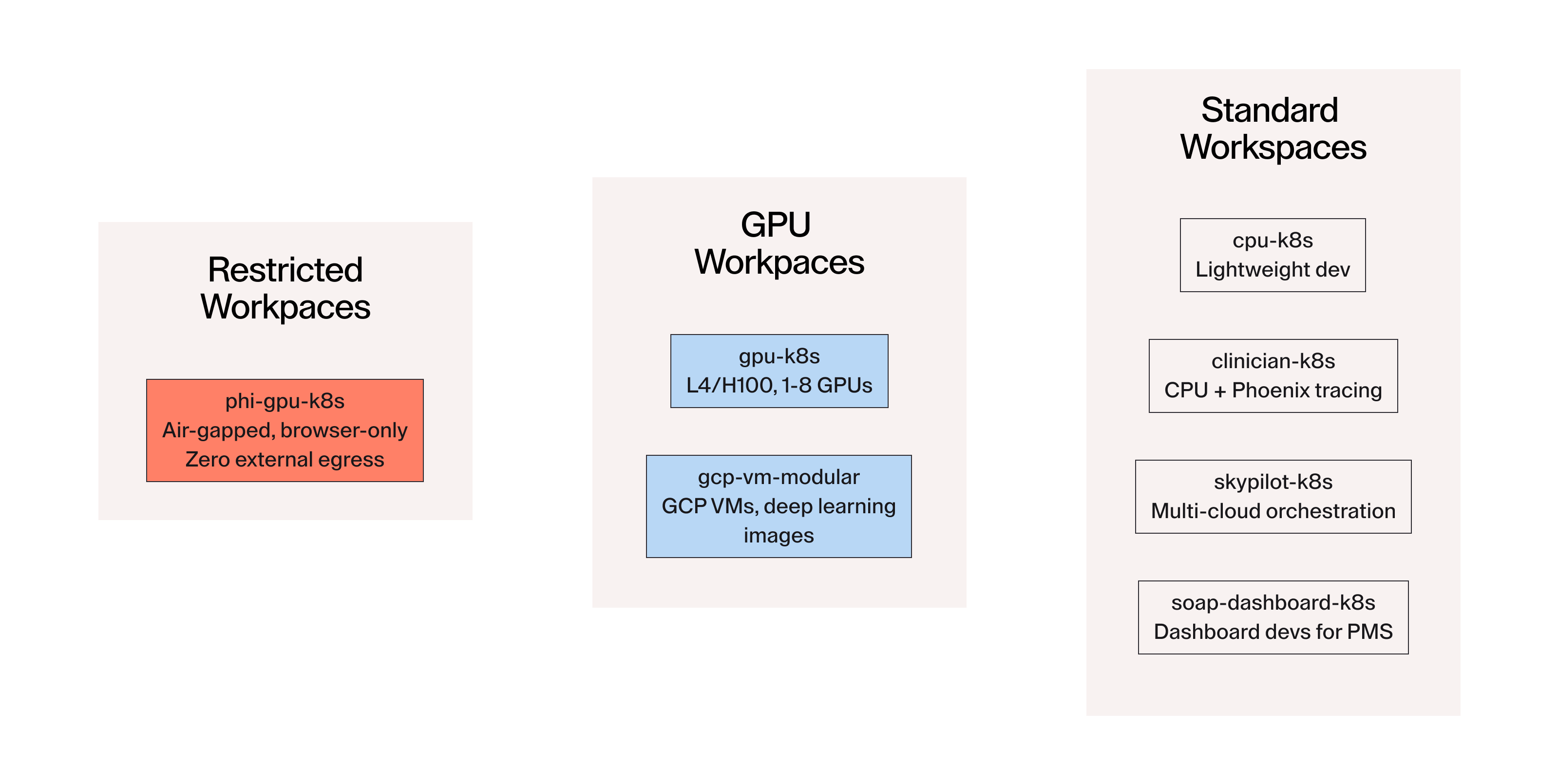
Workspace templates grouped by access tier: restricted PHI workspaces with zero external egress, GPU workspaces with L4/H100 access, and standard workspaces for dev, clinical science, multi-cloud orchestration, and dashboard work.
Each template exposes mutable parameters: CPU, memory, disk, GPU type and count, repo URL, and IDE preference. Developers tune their own environments within guardrails set by the template. No admin intervention required. /modules/resources/ defines standardized parameter ranges and cost definitions. /modules/utilities/ handles reusable setup tasks: git clone, IDE configuration, GCS bucket mounting, and logging. Changing a default in one place propagates everywhere.
Compliance encoded, not enforced
For workspaces that handle patient data, compliance requirements aren't a checklist in a UI. They're structural.
Abridge designed the phi-gpu-k8s template to enforce HIPAA-aligned constraints at the network layer using Istio ServiceEntry and Sidecar configs: zero external egress by default, with allow-listed endpoints only (PyPI, GCS, BigQuery, internal services). File transfer is disabled at the agent level. Browser-only access is enforced—no port forwarding, no direct shell access. These aren't settings a user can accidentally misconfigure. They're baked into the network policy definitions committed to version control.
Abridge also built a clear separation between ephemeral and persistent data models into the template design itself. Category I data persists on workspace volumes across restarts. Category II workspaces run ephemerally—no data written to disk, no state retained between sessions. The distinction is enforced by how the templates are architected, not by policy documentation that developers have to remember to follow. When your product handles sensitive clinical conversations, the difference between "policy says don't do this" and "the system makes it impossible" is significant.
CI/CD for infrastructure changes
Template updates don't require anyone to log into a console. Abridge built two GitHub Actions workflows to handle the full template lifecycle. The deploy workflow fires on merge to main or manual dispatch, running terraform init / validate / plan / apply per template and versioning each by commit SHA. The test workflow fires on every PR touching templates or modules, building a test matrix and running parallel tests against scenario configs in tests/templates/*.json before anything reaches production.
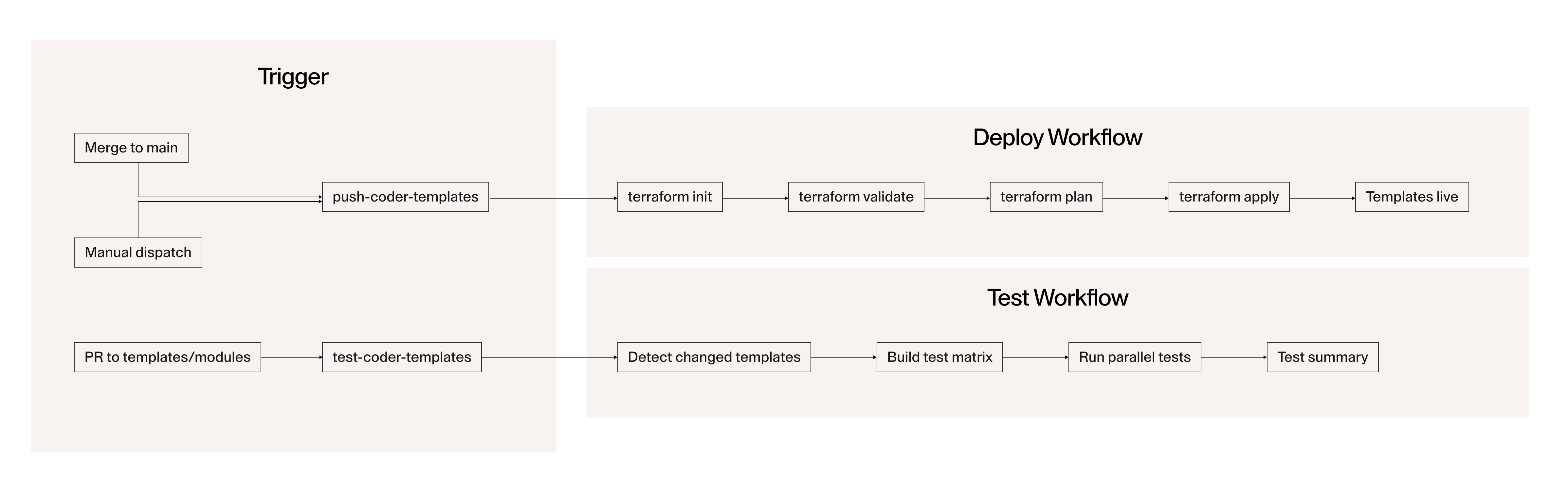 Two GitHub Actions workflows handle all template lifecycle management: the deploy workflow fires on merge to main or manual dispatch; the test workflow fires on every PR touching templates or modules, running parallel tests against scenario configs before anything reaches production.
Two GitHub Actions workflows handle all template lifecycle management: the deploy workflow fires on merge to main or manual dispatch; the test workflow fires on every PR touching templates or modules, running parallel tests against scenario configs before anything reaches production.
ML infra engineers can safely iterate on templates in the dev environment and validate against staging before anything touches production users. The same rigor Abridge applies to application code applies to the infrastructure that runs it. That consistency matters when your infrastructure changes can affect GPU workloads running sensitive model training jobs.
Self-service onboarding that actually works
The developer flow today:
- Added to the appropriate GitHub org team
- VPN connection
- GitHub SSO into Coder
- Template selection and parameter tuning
- Workspace provisions automatically with repo cloned, tooling configured, and cloud access authenticated
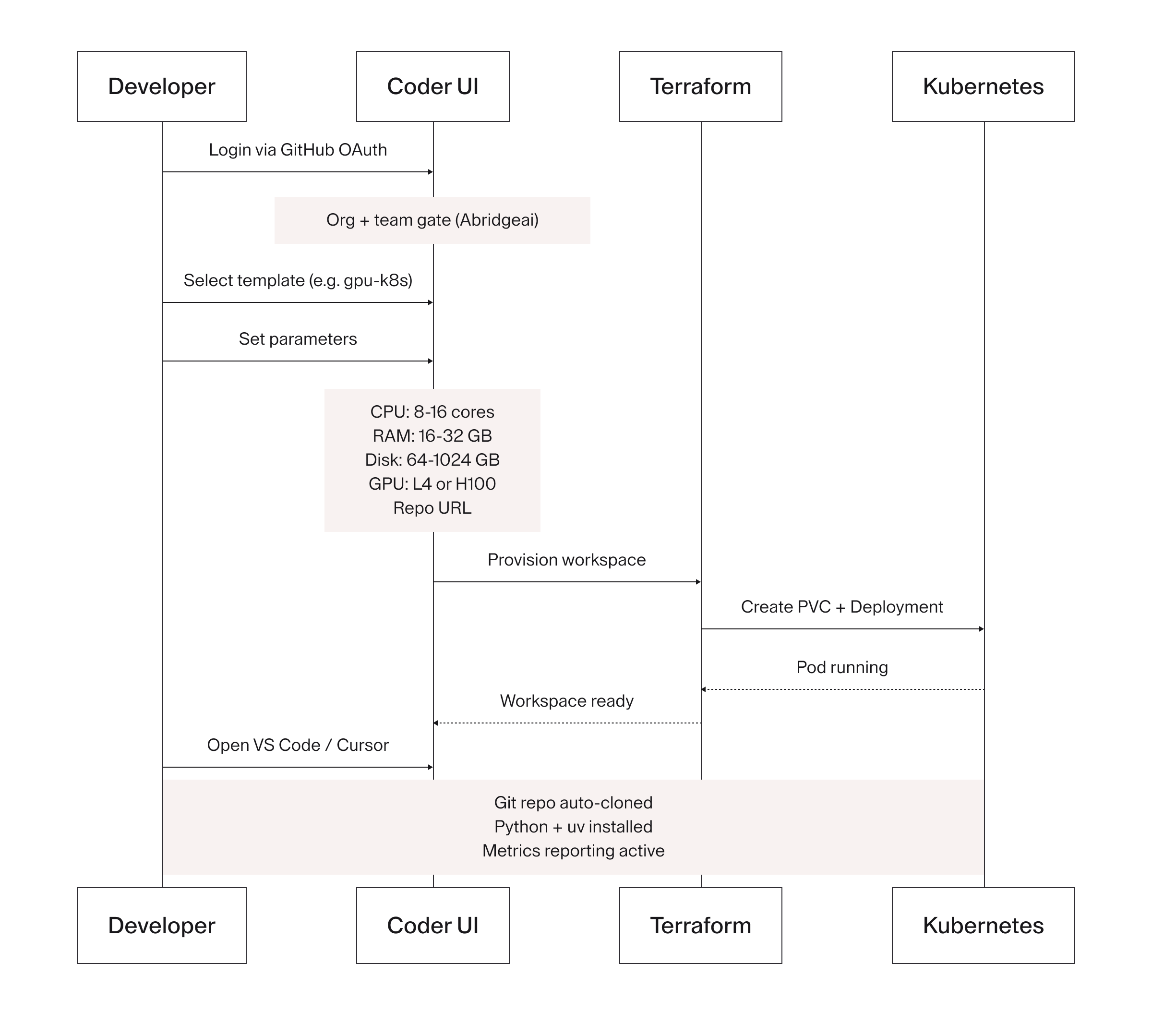 End-to-end workspace provisioning: GitHub OAuth with org and team gating, template selection with user-tunable parameters, Terraform-driven PVC and Deployment creation in Kubernetes, and a workspace that arrives with git repo cloned, Python and uv installed, and metrics reporting active.
End-to-end workspace provisioning: GitHub OAuth with org and team gating, template selection with user-tunable parameters, Terraform-driven PVC and Deployment creation in Kubernetes, and a workspace that arrives with git repo cloned, Python and uv installed, and metrics reporting active.
Every repository includes a coder_setup.sh that handles virtualenv creation, dependency installation from private registries, service-specific tooling, and pre-commit hooks. Abridge made this a deliberate architectural choice: templates stay minimal and stable, while repos own their own setup logic. A new ML scientist who joined recently had their first training job running on day one -- same environment as the rest of the team, no specialized help required.
GPU cost as an engineering problem
GPU waste is an expensive problem at any ML-focused company, and it tends to be a social problem as much as a technical one. Jobs finish but instances stay live.
Abridge addressed this structurally through the template design. Auto-stop policies are configured per template so idle workspaces shut down automatically. Compute allocations are right-sized to workload type at the template level rather than left to individual developers to decide. Resource limits are consistent and predictable across the fleet because they come from the same shared modules. The result was immediate: significant decommissioning of stray cloud VMs and a material reduction in GPU spend, without developers feeling constrained because the system handles it automatically.
Abridge also runs three independent environments—dev, staging, and production—each with independent access controls, quotas, and policies. The separation gives ML Infra engineers room to test infrastructure changes safely without touching production workloads, which at our GPU spend levels is not a theoretical concern.
What Abridge learned building this
The decisions that made the biggest difference weren't about picking tools. They were about where to draw architectural boundaries.
1. Keeping templates opinionated was the right call
Abridge started with a small set and resisted the urge to add templates every time someone had a slightly different use case. The Pareto principle holds: seven well-maintained templates with solid shared modules cover the vast majority of our workloads. The discipline required to say "fit your workflow to an existing template" pays dividends in maintainability.
2. Separating setup logic from template logic was the other key decision
Early on, templates were doing too much. Moving repo-specific setup into coder_setup.sh kept templates stable and let teams iterate on their own tooling without waiting for an infra change. It also made the compliance boundary cleaner: templates encode what is and isn't allowed at the network and compute level, and repos handle everything above that.
3. The ephemeral vs. persistent data model required more upfront thought than we expected
Learning that the hard way—discovering that data doesn't persist after a workspace restart —is a bad experience for researchers in the middle of a training run. We now document it explicitly, reinforce it in template descriptions, and provide shared persistent storage where the workload genuinely needs it.
As Abridge continues to scale, the infrastructure underneath has to scale with it. Fractional GPU allocation, better observability into workspace usage, and clearer template versioning are on the roadmap. The goal remains the same: get infrastructure out of the way so clinical scientists, ML researchers, and product engineers can focus on building the product that matters to our customers.

Taruj Goyal is an ML/Infrastructure Engineer/Claude Whisperer at Abridge who works on scalable developer platforms, GPU-enabled ML environments, Inference Optimization, and Infrastructure automation. His work focuses on making it faster and safer for engineers, researchers, and clinical teams to build and run AI systems, especially in regulated healthcare settings.

Senior Machine Learning Engineer at Abridge
Sam is an engineer and researcher working on Abridge's AI evaluation platform. She cares deeply about model quality, and her goal is to make it easier, faster, and more enjoyable for her teammates to deliver excellent AI product experiences.
Subscribe to our newsletter
Want to stay up to date on all things Coder? Subscribe to our monthly newsletter for the latest articles, workshops, events, and announcements.