


What 100 Engineering Teams Revealed About AI Maturity and What to Do About It
This year, Coder released its AI Maturity Self-Assessment alongside a five-stage framework for understanding how engineering organizations adopt agentic AI. The goal was to give engineering leaders a concrete way to benchmark where they stand and plan what comes next. Over several weeks, 100 engineering organizations completed the assessment.
The pattern in the responses was immediate and consistent. These are not organizations debating whether to use AI. The vast majority are already running agents. The gap is between that adoption and the infrastructure, governance, and measurement needed to support it.
Four numbers from the assessment define the core tension:
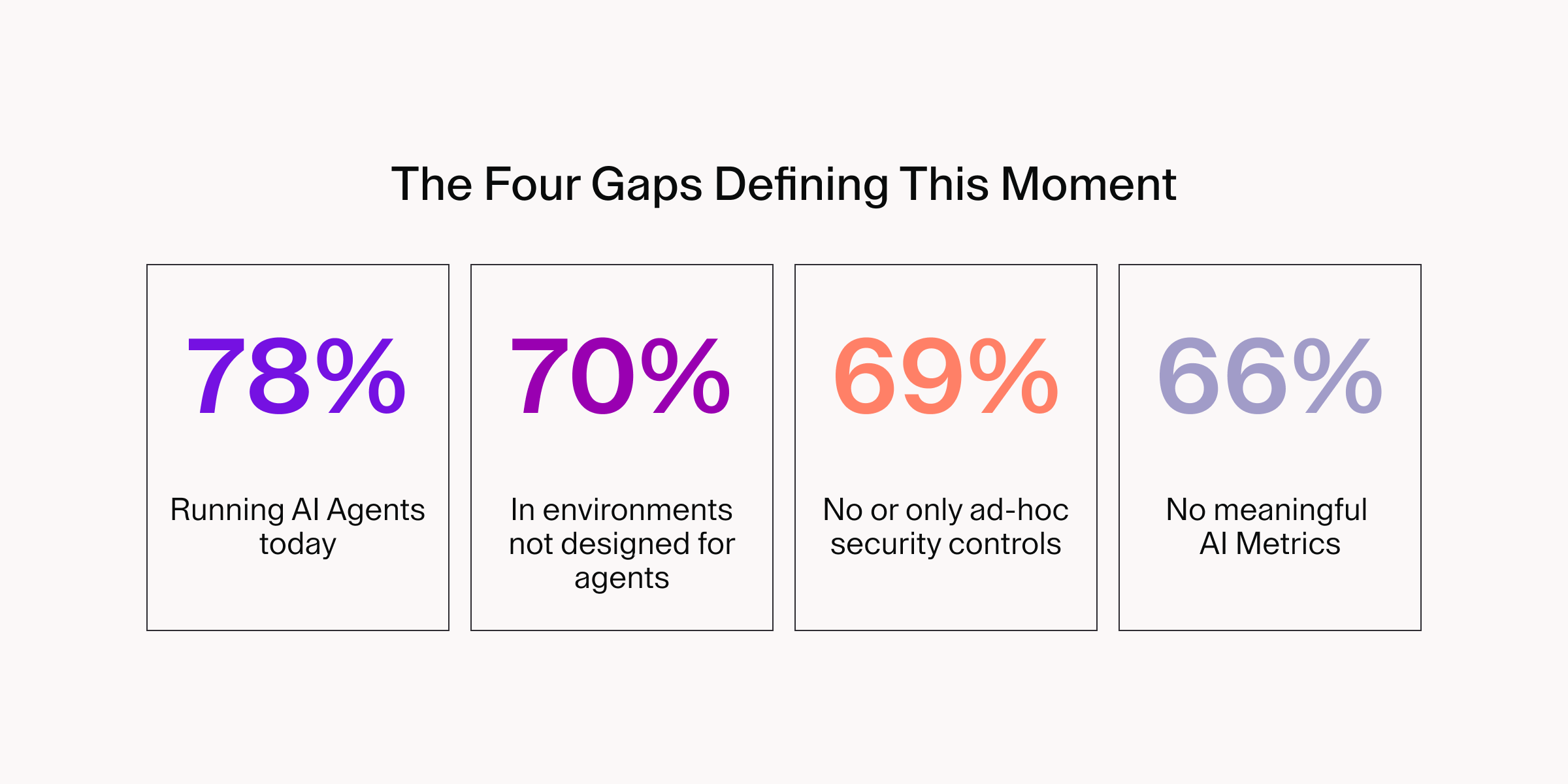
Each of these gaps showed up independently across findings. Together, they tell a single story: adoption is real, and the operating model to match it is not. Here is what the data revealed and what the organizations pulling ahead are doing differently.
Finding 1: Most teams have moved past code completion
The most striking finding from the assessment is that individual AI productivity tools are no longer the whole story.
How teams currently use AI:
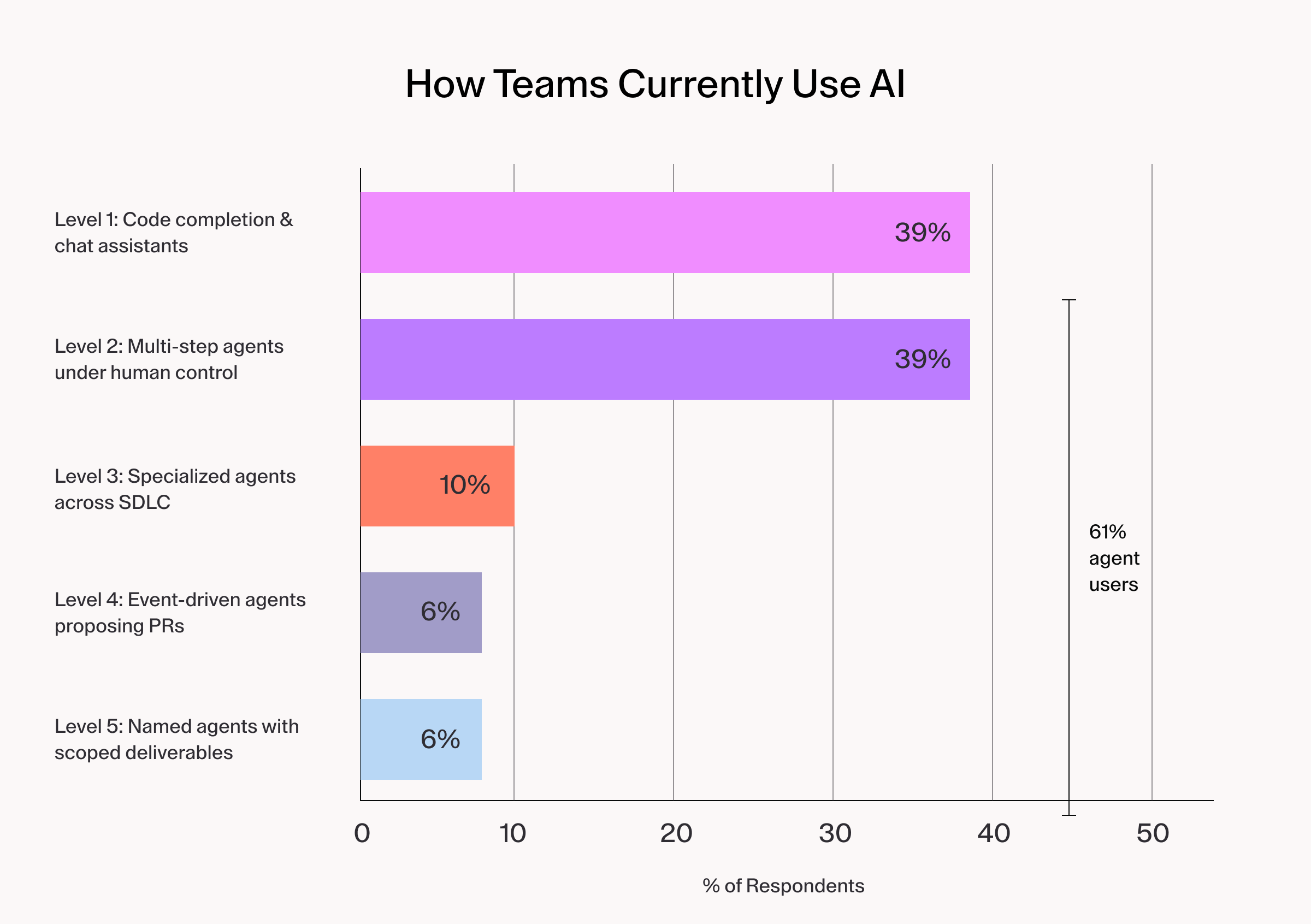
Those running agents of any kind represent 61% of respondents. A 2024 GitHub survey found that 92% of developers were already using AI coding tools in some form and the move from passive suggestion to active agent execution has accelerated. The era of AI as a glorified autocomplete is over.
But the concentration tells a more specific story. Nearly 80% of respondents are still at the first two stages of the maturity model: Code completion tools and human-directed local agents. Only a small fraction have moved to cloud-based agents that respond to event triggers, and fewer still are experimenting with agents that identify their own work from product roadmaps or coordinate across the full development lifecycle. The field is early. Organizations that have not yet formalized their approach are not behind. They are exactly where structured adoption should begin.
The risk profile, however, shifts meaningfully between those stages. At Level 1, the primary concern is shadow IT proliferation as engineers adopt tools without security oversight. At Level 2, the stakes rise: agents handle entire features across dozens of files, integrate with version control and project management tools, and require consistent environments and permissioned data access to behave predictably. Most teams making that leap are not yet making the corresponding infrastructure investments.
Recent supply chain incidents have made this concrete. When compromised npm packages harvested GitHub tokens and cloud credentials from developer workstations during the Shai-Hulud 2.0 attack, the organizations that contained the damage fastest had already moved development off local laptops and into governed environments.
Finding 2: Agent usage is outpacing environment readiness
If most teams have moved past code completion, the next question is whether the infrastructure underneath them has kept pace. For the majority of respondents, it has not.
The assessment asked how standardized developer environments are today, and the gap between adoption and the numbers diverge sharply from AI adoption rates.
Here's the current state of developer environment standardization:
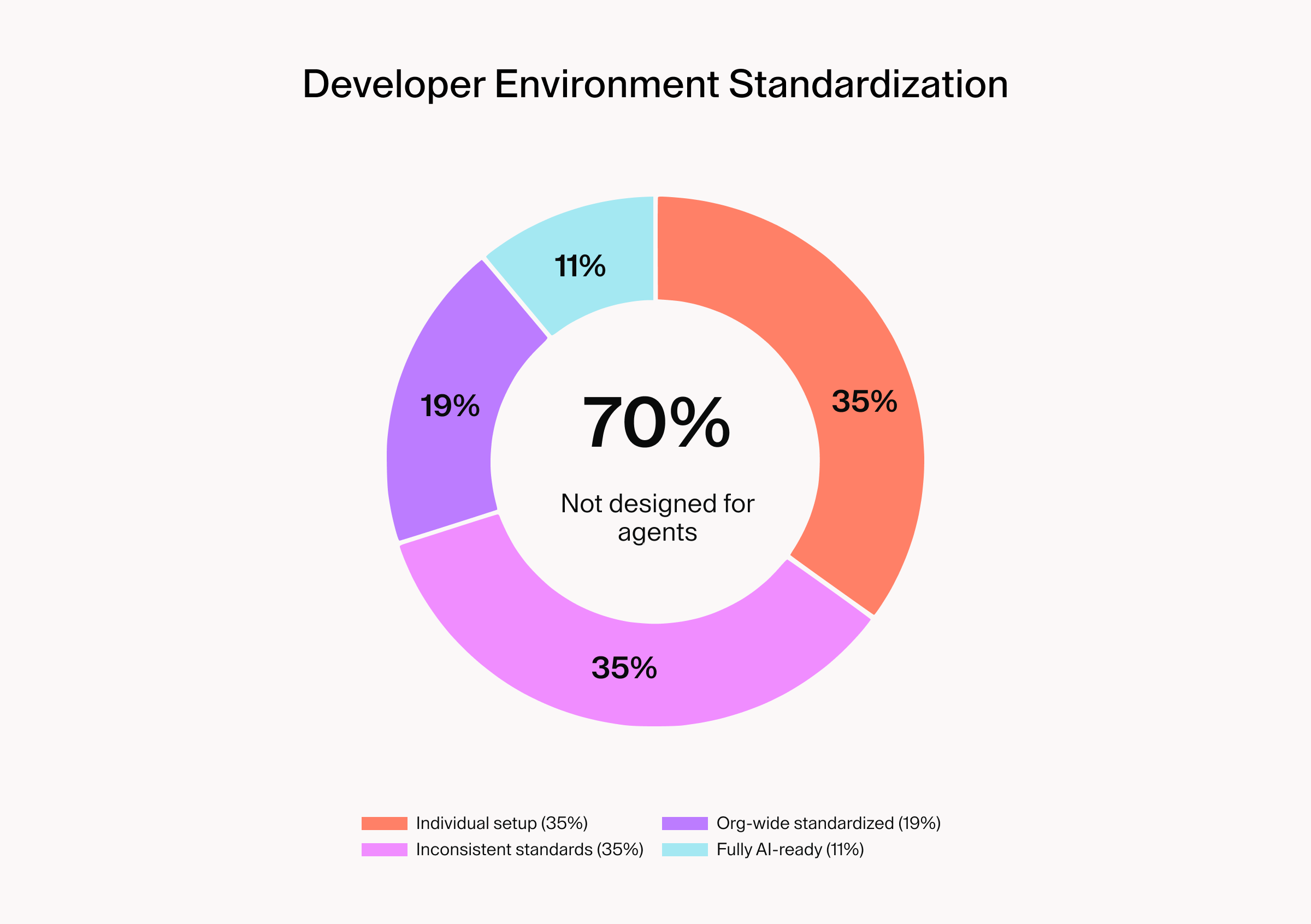
70% of respondents are running AI agents in infrastructure that was never designed to support them.
This gap is not abstract. Standardized environments are the execution layer that makes agent behavior predictable, auditable, and safe. Without them:
- The same agent instruction produces different results on different machines
- Security controls cannot be enforced uniformly across teams
- The traceability required by enterprise compliance frameworks does not exist
- Incidents are difficult to investigate or attribute after the fact
McKinsey's AI transformation manifesto makes this point directly: tech platforms are strategic assets that "determine a company's execution speed" and "enable AI to scale responsibly," and without digital trust, there is "no right to deploy AI." The assessment data confirms both principles as lived realities for the majority of respondents. Organizations that skip the foundational infrastructure work cannot build the trust or repeatability that scaling demands.
The fix is conceptually simple but organizationally hard: agents and humans need to work in the same governed environments, under the same constraints. When that parity exists, output is reproducible, auditable, and easy to hand off in either direction. When it doesn't, every team is running a slightly different version of reality, and incidents become impossible to attribute after the fact.
The Claude Code source map leak in March 2026 illustrated the upside of centralized environment management. Organizations that controlled tool versions through workspace templates were insulated from the downstream exploitation, while those relying on developers to pull from public registries were exposed within hours.
Finding 3: Governance exists on paper but not in practice
Environment standardization is one half of the readiness equation. The other is governance: who is allowed to do what, under what constraints, and with what level of oversight.
The assessment data suggests that most organizations have started thinking about this, but few have built anything enforceable.
This is how organizations approach AI governance:
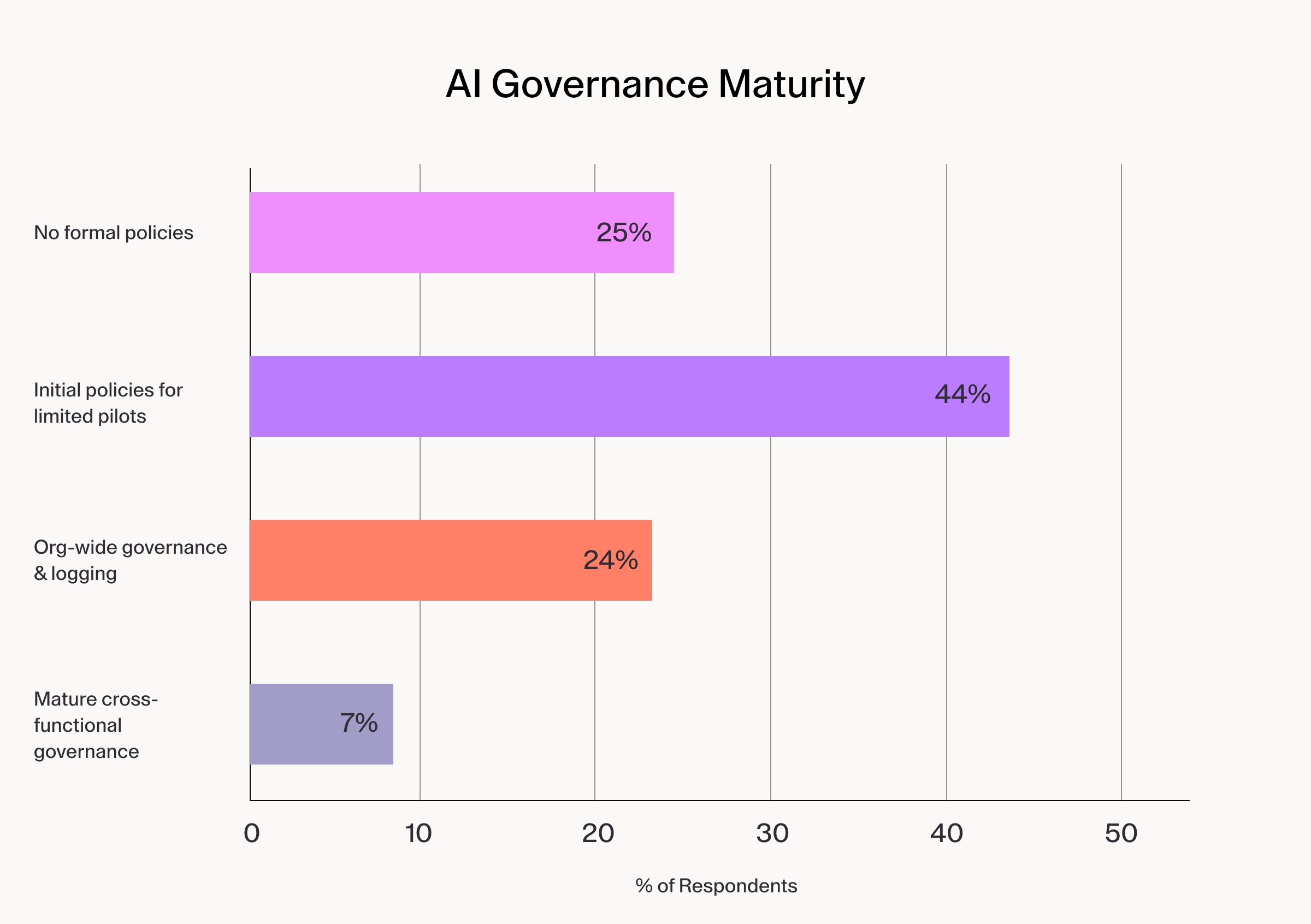
Only 31% have reached organization-wide governance or better. The security picture underneath those numbers is sharper still:
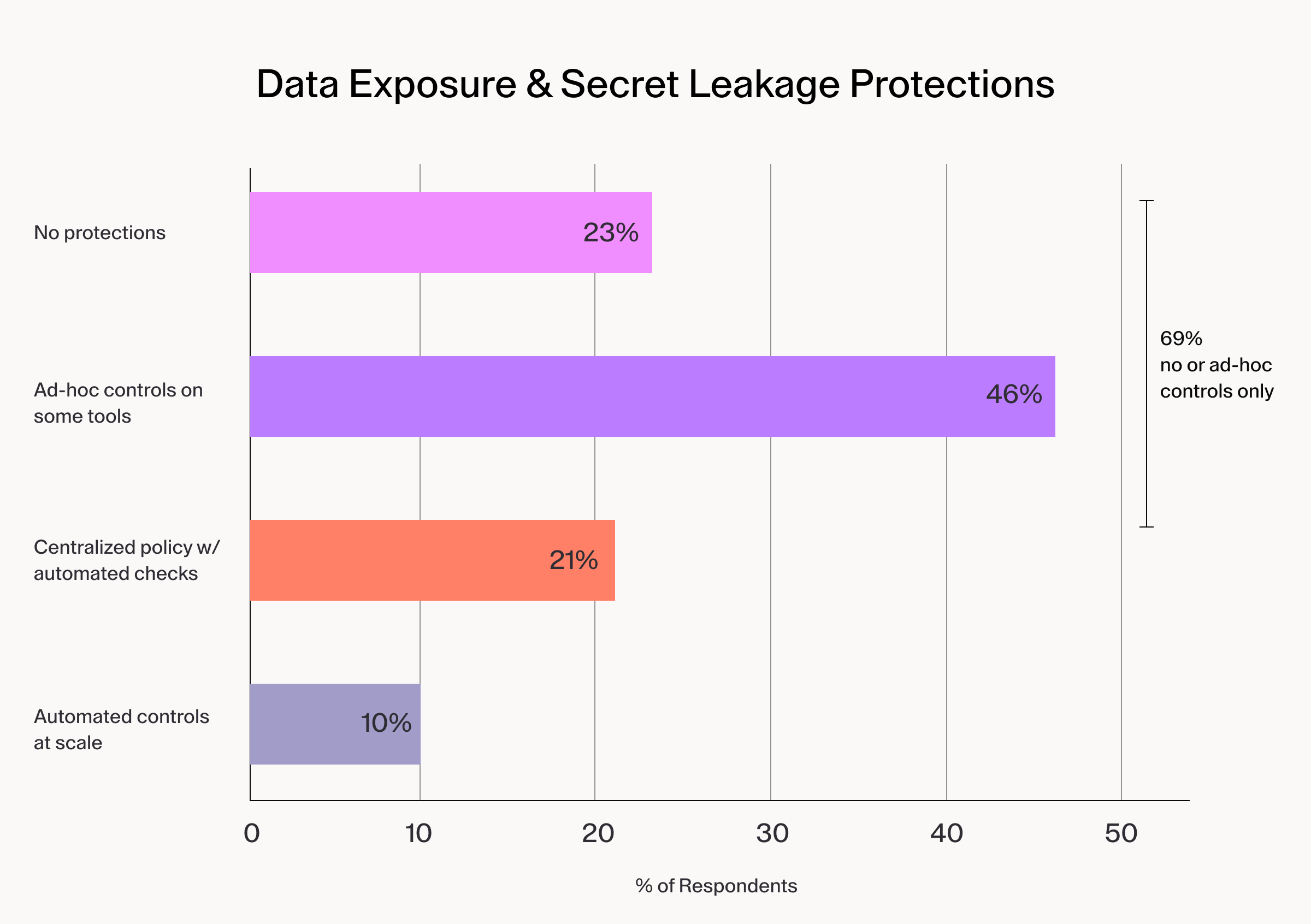
The takeaway is that policy frameworks developed for human developers are not automatically extending to cover the agents those developers are now directing.
Most organizations in the 44% pilot category are running binary governance: a tool is either approved or blocked. That works for human-scale adoption. It breaks down when agents operate at machine speed across dozens of repositories, each with different sensitivity levels, different compliance requirements, and different risk profiles.
The organizations closing this gap are moving toward tiered governance, where access and oversight scale with risk. Low-risk operations are enabled by default. Medium-risk work requires review. High-risk changes trigger multi-approval workflows. A centralized decision point applies those policies consistently across tools and teams, logging every AI-assisted operation with enough detail to reconstruct what happened and why. Automated checks for secrets, static analysis, and policy violations block unsafe patterns before code ever reaches review.
Financial institutions have been early adopters of this layered approach, driven by regulatory pressure that makes the cost of getting it wrong existential. The pattern they are building, centralized LLM gateways for observability, process-level network isolation for agents, governed workspaces for auditability, is the same pattern the assessment data suggests every organization scaling agents will eventually need.
Finding 4: Adoption strategy reflects the governance gap
The adoption patterns respondents described mirror the governance data closely.
72% of teams are scaling AI from informal experimentation and carrying every unresolved security question with them into production.
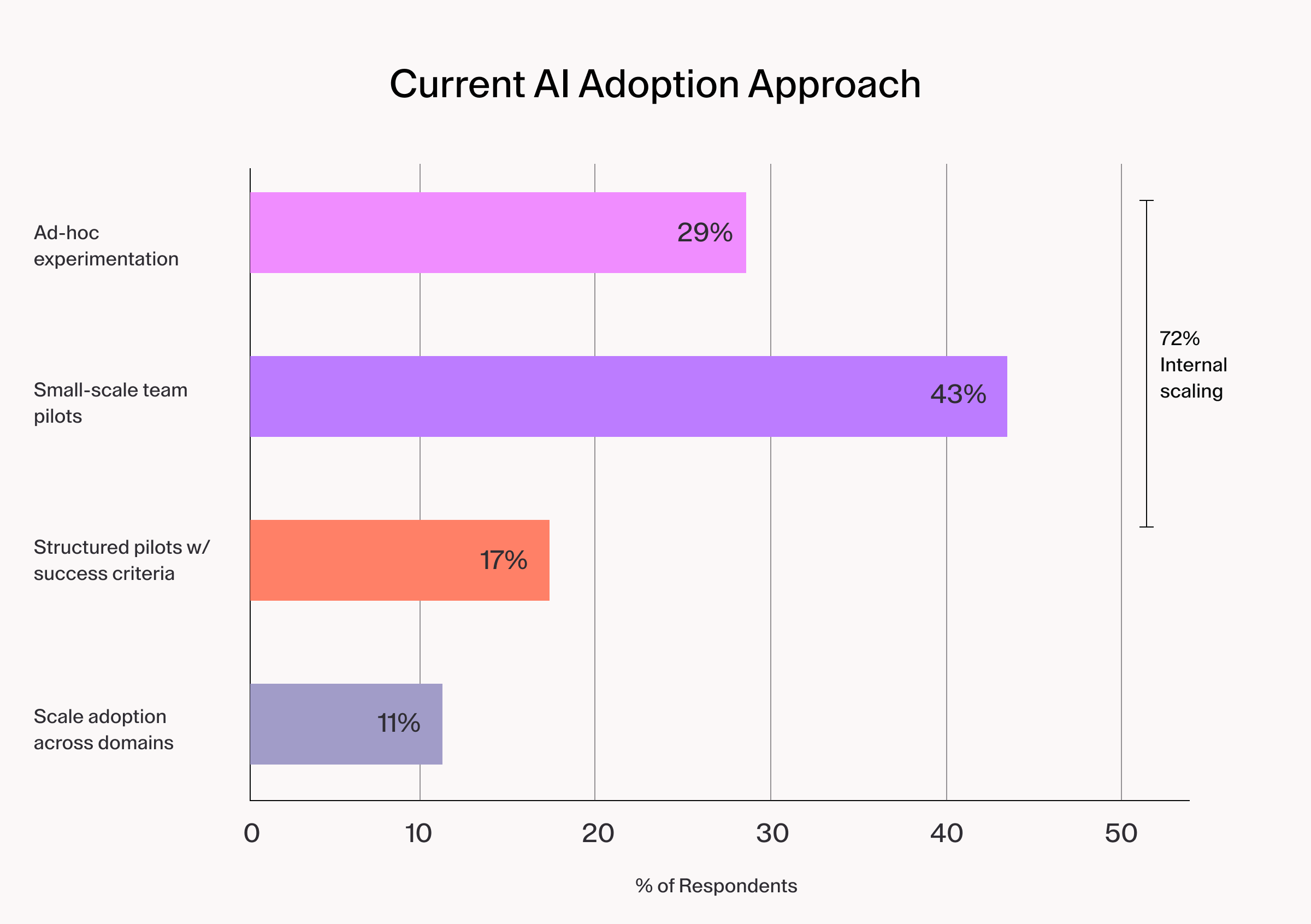
According to a Gartner analysis of AI deployment failures, the majority of failed enterprise AI initiatives collapsed not because the AI technology was inadequate, but because the organizational operating model was not built to support it.
The disconnect is clearest when you look at what the transition from local agents to cloud-based automation actually requires: standardized environments, permissioned data access, comprehensive logging, and cost monitoring. The majority of teams in this transition zone have completed none of those steps. They are running agents that need governed infrastructure on infrastructure that was built before agents existed.
This is what structured adoption looks like in practice:
- Start with one to two teams.
- Select high-value and low-risk use cases like test generation, documentation updates, and code refactoring.
- Establish daily learning loops to gather quantitative metrics and qualitative feedback.
- Define explicit criteria for expansion like zero AI-related security incidents, measurable productivity improvements, and positive developer feedback.
- Only expand when those criteria are met.
The maturity model's adoption roadmap phases this over 12 months, starting with inventory and policy, moving through focused pilots, and expanding to workflow automation only after environment parity and security controls are validated.
The organizations that move through this process deliberately are the ones that reach the genuine ROI inflection point: multiple agents operating in parallel on routine work, while engineers focus on architecture, problem framing, and review.
Finding 5: How teams measure success reveals what they value
Perhaps the starkest data point in the assessment involves measurement.
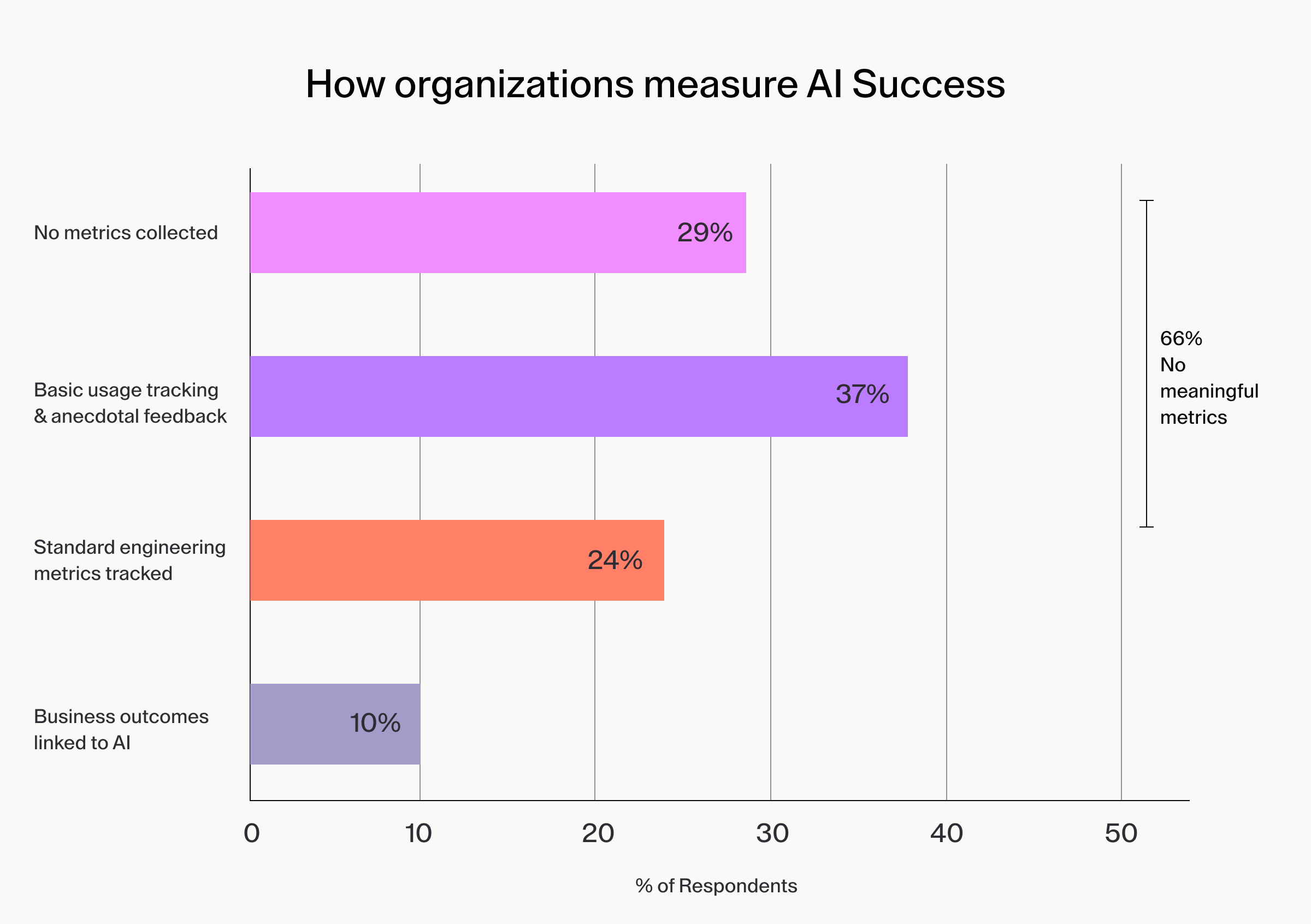
Only 10% of respondents have linked AI adoption to business outcomes. The other 90% cannot yet answer the question that matters most to executive stakeholders: "Is AI actually working?"
Measurement shapes investment. The metrics that actually signal value fall into four categories:
- Productivity and flow (lead time for changes, throughput per engineer, PR cycle time from creation to merge)
- Quality and risk (post-merge defects, security exceptions avoided, mean time to restore service)
- Developer experience (satisfaction with AI-enabled environments, signal-to-noise in code reviews)
- Cost (AI spend per unit of value delivered, environment utilization efficiency).
Without a framework that tracks these outcomes alongside adoption, the case for continued investment cannot be made. An LLM gateway that logs every model interaction with attribution to teams, projects, and workflows makes this measurement practical by turning agent activity into queryable data rather than a black box.
The teams at the top of the maturity curve treat measurement as infrastructure, not an afterthought. An executive dashboard tracking delivery, quality, security, developer experience, and cost is the mechanism that enables evidence-based expansion and stops bad investments before they compound.
What engineering leaders should do now
Agentic AI is no longer experimental for most engineering organizations. It is operational. Agents are already running in your codebase, directing workflows, proposing code changes, and in some cases taking on entire deliverables. The organizations pulling ahead are the ones building the operating model to match.
The real risk sits with the 44% running limited pilots under initial policies, moving toward broader agent usage without the infrastructure to support it. The gap between "we have some policies" and "we have organizational-level governance and environment standardization" is where most incidents occur and where governance debt compounds fastest.
Based on both the assessment data and the patterns of organizations that have successfully scaled agentic AI, four priorities stand out:
Standardize environments before expanding agent scope. Consistent, AI-ready infrastructure is the prerequisite for safe scale. Environments must maintain parity between human and agent workflows. Until they do, governance is theoretical.
Establish a centralized decision point with logging. Every AI-assisted operation, whether initiated by a human or an agent, should be recorded with enough detail to reconstruct what happened, when, and why. An LLM proxy that applies policy, routes requests to appropriate models, and maintains a complete audit trail is the mechanism that makes this practical at scale.
Move from ad-hoc to structured pilots with defined success criteria. Define what "working" means before expanding. Every informal pilot that scales carries its unresolved questions into production. The expansion criteria should be explicit: zero AI-related security incidents, measurable productivity gains, stable environment performance, and positive developer feedback.
Instrument outcomes, not just adoption. Usage metrics cannot tell you whether AI is working. Business outcomes like cycle time, defect rates, security exceptions avoided, and cost-to-serve can. Deploy a dashboard that tracks these before scaling, not after.
The data shows that most organizations have already made the decision to adopt agentic AI. The question now is whether the infrastructure and governance to support that decision will catch up before the risks do.
The organizations that get this right will ship faster with fewer defects, demonstrate compliance by design, and create space for engineers to do higher-leverage work. The ones that scale chaotically will spend the next 18 months retrofitting controls and watching delivery slow under the weight of governance debt that accumulated in the meantime.
Take the AI Maturity Self-Assessment to benchmark where your organization stands today. Read the full AI Maturity Model whitepaper for the complete five-stage framework, risk mitigation controls, and a 12-month adoption roadmap.

Senior Marketing Manager, EMEA

Kodie is a content and comms professional focused on enterprise and developer tools. A passionate open source advocate, he's all-in on content engineering, using vibe coding workflows to craft stories at the speed developers ship code.
Subscribe to our newsletter
Want to stay up to date on all things Coder? Subscribe to our monthly newsletter for the latest articles, workshops, events, and announcements.